Overview
DNA Match Analyzer was created to assist in figuring out where a person who took a DNA test fits into a family tree. The test taker is generally an adoptee looking for birth parents.
What does DNA Match Analyzer Do?
Full Tree Analysis
DNA Match Analyzer takes as input a Gedcom file annotated with the strength of the DNA connection that the test taker shares with people in the tree, and produces as output a report that shows relationships between the test taker and people in the tree. See the detailed instructions for more information.
Person Specific Analysis
Note: If you are new to DNA Match Analyzer, this is probably not what you want to do.If you have a hypothesis about where the tester might fit into a tree, DNA Match Analyzer can help you test that hypothesis by producing a report for how well that location in the tree fits with the DNA provided. To use this feature, create a fake person at that location in the tree, add the word "analyze" to the suffix of data attached to that person and submit the Gedcom. If there is already a suffix, you can separate the parts with semi-colons (";"). See the detailed instructions for more information.
What does DNA Match Analyzer NOT Do?
DNA Match Analyzer does not do any magic. It attempts to deduce where a tester might fit into a tree based on shard matches by creating synthetic people and doing math. If the matches that are in the tree don't provide enough data for good conclusions to be drawn, it cannot draw good conclusions, and the output may not be very helpful.
What does DNA Match Analzyer's Output Look Like?
The output is broken into a number of sections. The first section is simply some a text overview of what has been done, the second details the matches, and the third contains the match summary reports. This sample report is generated from my matches which share < 600cM (the names have been changed to protect identities). You can download the Gedcom it was generated from if you would look to see the input (or try it yourself).
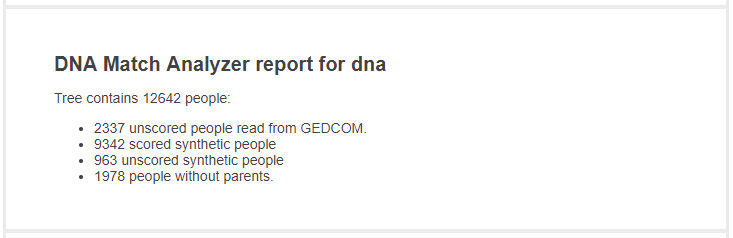
Tree Summary
The output begins with a text summary, and then contains a summary of the inputs:
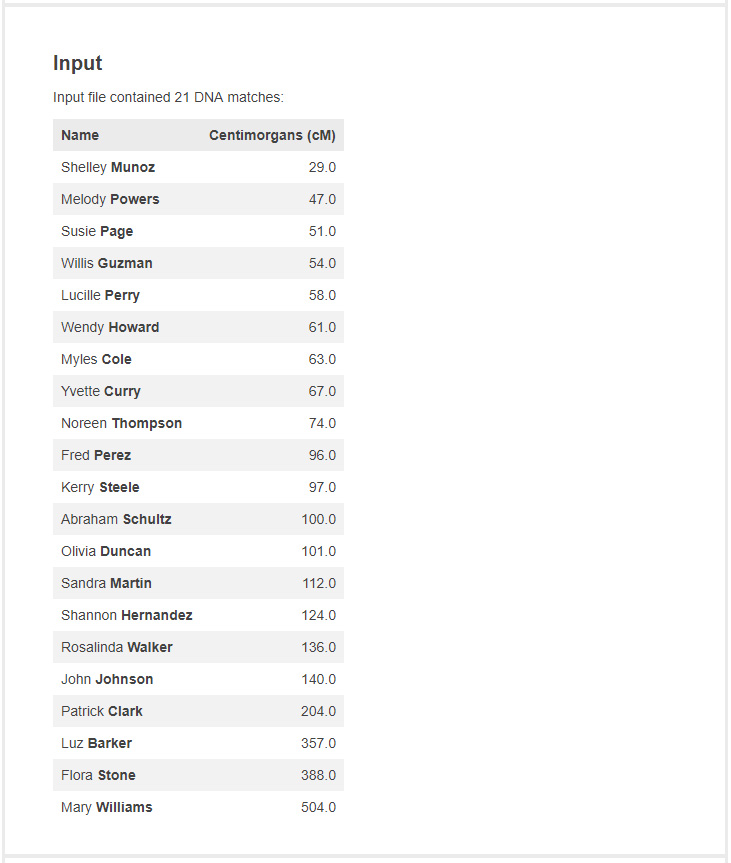
Match Listing
It then lists the matches found embedded in the tree. It is important to double check that all the matches you expected to be in the input are there:
Synthetic People
People that are in the input tree are referred to as real people. In order to help consider “all possibilities”, the program creates several different kinds of synthetic people. Unless you understand how they are created and named, you will not be able to understand the report. The first step the program takes is to fill in the tree by ensuring at all real people have two parents, a full sibling and a half sibling for each parent.
To do this, the following people are created:
-
Every interesting person in the tree needs to have two parents. If an interesting person has:
- two real parents in the tree, no synthetic parents are needed, so none are created.
-
one real parent is in the tree, a second synthetic parent is
created and named “Parent of
”. -
no real parents in the tree, two synthetic parents are
created. The first is name “Parent of
” and can appear in the output. The second is interesting and will not show up in the output
-
Now that every real person has two parents, a synthetic sibling is
created for each interesting person. This sibling is named “Child
of
and ” Only one synthetic full sibling is created for a pair of parents. -
In order to allow for the possibility unknown NPE children, a
synthetic child is created for every interesting person and named
“Child of
”. The other parent for this child is not included in the tree (it is assumed they are unknown).
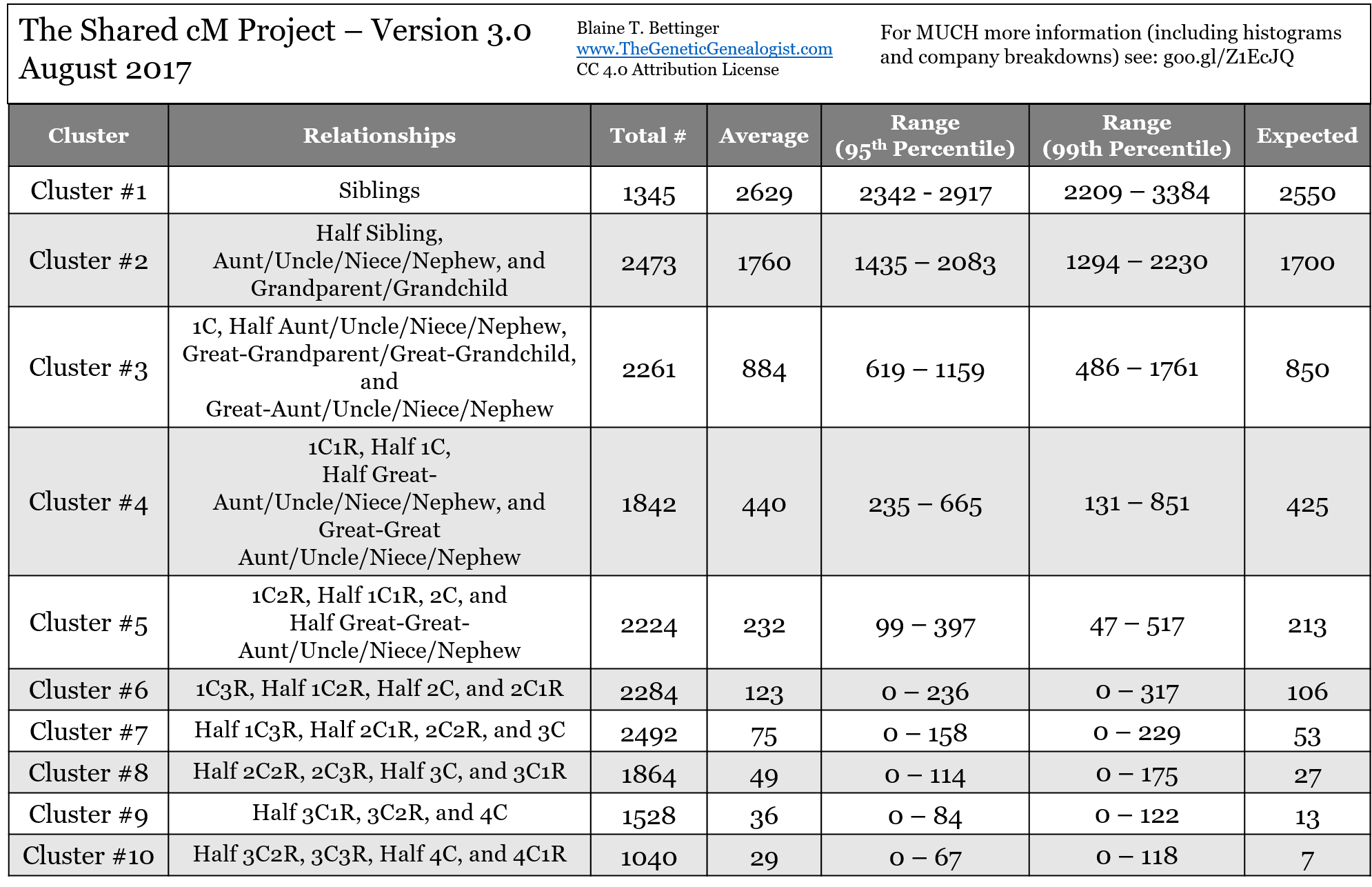
Scoring
The program computes a score for every person it analyzes. The score is based on whether the number of cMs shared with the match fit within the 95 percentile values from the Shared cM project's table of DNA matches. The score is the total number of cMs that were within the expected range from the minus the number of cMs that were not within the expected range. More precisely, the score is computed as:
{kind=link}
Score is initially set to 0. For every match in the tree:
- The program computes the relationship between the person being analyzed and the match using their positions in the input tree. It uses this information to look up the corresponding low, average and high values in the Shared CM project chart’s 95 percentile column (the expected values).
-
It then compares the value encoded in the tree (the actual)
value to the expected high and low values. If the
actual value is:
- between the expected low and high, the actual number of cMs is added to the score this match was within predicted range.
- not between the expected high and low the score is reduced by the larger of the expected average cM and the actual cM .
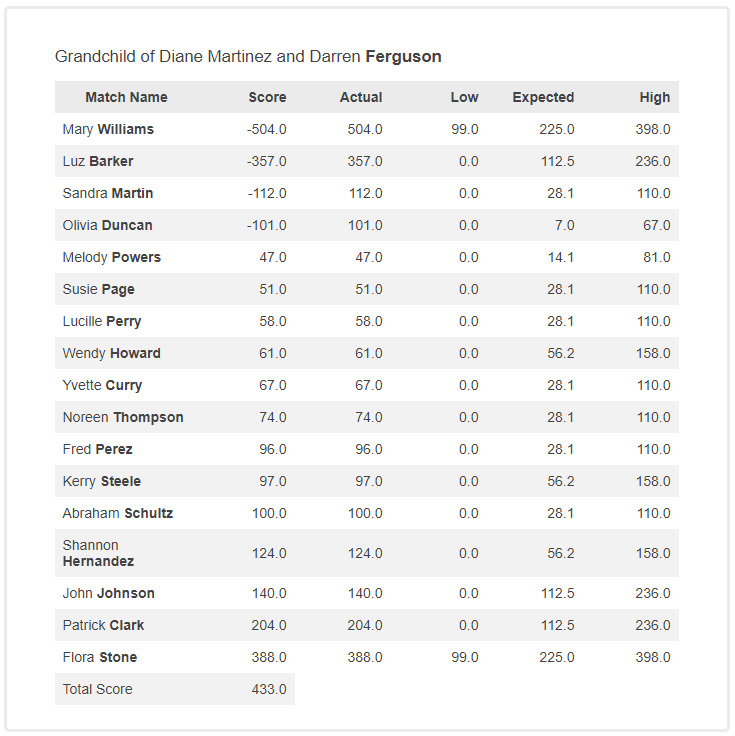
Here is a sample of a single analysis from the program:
Interpreting the results
Because DNA transfer is random, there is no "sure thing" in interpreting the results, and interpreting less obvious results is more of art than science.
In the sample above, the fact that two high matches (504 and 357) cM do not fit, it is fairly obvious that the person who took the test is not the "Grandchild of Diane Martinez and Darren Ferguson".
How do I get started using DNA Match Analyzer?
You must add your DNA matches to your family tree, export the tree and upload it to DNA Match Analyzer. See the Detailed Instructions page for information on getting started.